Wer eigene Projekte oder ggf. einen Onlineshop betreibt, hat sicherlich das Bedürfnis seinen Besuchern und Nutzern ähnliche Produkte vorzuschlagen – vor allem, wenn die Wunschauswahl aktuell nicht vorhanden ist oder nicht mehr geliefert werden kann. Die meisten Empfehlungssysteme basieren auf simplen Datenbankabfragen á la „Produkte in der gleichen Kategorie mit den gleichen Tags“ oder „Produkte, in deren Inhalt der Inhalt/Name/Kategorie des aktuellen Produkts vorkommt“. Auch auf Basis von Text lassen sich so „passende Artikel“ bestimmen (Artikel in deren Inhalt der Name des aktuellen Artikels (teilweise) vorkommt z.B.). Wer mich etwas näher kennt, der weiß, dass ich ein größeres Projekt habe, welches unter „fernseher-kaufberatung.com“ zu erreichen ist und dessen Namen im Grunde schon alles sagt. Dort habe ich bisher auf diese „Ähnliche Produkte“ Funktion verzichtet. Bei der Auswertung meiner Daten bin ich aber zum Entschluss gekommen, dass das keine schlechte Idee wäre. Integriert werden sollte es zum einen im Kaufberater selbst (Fragen beantworten, passende Produkte vorgeschlagen bekommen) sowie auf den Produktseiten. Ziel ist es also gewesen zu jedem Produkt wirklich gute passende Alternativen anzeigen zu lassen. Und das ist gar nicht so einfach.
Machine Learning, Word2Vec, scikit-learn
Ein Thema, was mich aktuell sehr bewegt ist „Maschinelles Lernen“. Ich beschäftige mich aktuell stark damit, nehme an kleineren Wettbewerben teil in denen Modelle zur Klassifikation verschiedener Daten gebaut werden müssen ( und schneide mittlerweile ganz gut ab 🙂 )! Dabei verwende ich u.a.
Google Tensorflow oder
scikit-learn. Beides sind Werkzeuge, die man aus dem Bereich der Statistik oder der „künstlichen Intelligenz“ ganz gut kennt. Als Betreiber von Portalen, die vor allem auf Informationen basieren, bin ich mittlerweile recht gut mit Textanalyse vertraut. Auch hierzu gibt es innerhalb von scikit-learn richtig interessantes Zeug. Word2Vec ist ebenfalls so ein Thema, was mir persönlich nicht viel bringt, aber im Bereich Suchmaschinenoptimierung immer mehr im kommen ist. Die wirklich interessanten Dinge, werden da wohl aber noch kommt.
Jetzt liegt es also gar nicht so fern, dass ich einfach mal schaue, was es in diesem Bereich so gibt, um vielleicht eine Such nach „ähnlichen Produkten“ zu ermöglichen. Der Klassiker ist hier klar die „Nächste-Nachbarn-Klassifikation„. scikit-learn hat damit keine Probleme – man könnte sich mal die Folgende Seite anschauen:
sklearn.neighbors.KNeighborsClassifier.
Mit den Standardbibliotheken hab ich allerdings schon dermaßen viel zu tun, das ich etwas neues ausprobieren wollte
und dabei ist mir Spotify Annoy in den Sinn bekommen.
„Ungefähre nächste Nachbarn“ mit Spotify Annoy
Annoy steht für „Approximate Nearest Neighbors Oh Yeah“ und ist eine Implementation des gleichnahmigen Algorithmus in C++. Der Vorteil – es gibt auch ein Python Interface, so dass man es als Python Entwickler relativ einfach verwenden kann. Auf github findet man das Paket, falls man es selbst verwenden will.
Spotify verwendet es, um dir ähnliche Musik vorzuschlagen.
Um die Funktionsweise des Algorithmus zu verdeutlichen, nehme man ein simples Beispiel:
import annoy
features = 4
s = annoy.AnnoyIndex(features, metric="euclidean")
ps = [
[1,2,3,4], #0
[1,2,3,5], #1
[1,2,3,9], #2
[9,4,2,1], #3
[10,4,4,4], #4
]
for i,product in enumerate(ps):
s.add_item(i, product)
s.build(100)
Hierzu gehört dann auch das Speichern des aufgebauten Index. Vor allem bei vielen Produkten und Eigenschaften, dauert das Aufbauen eines Index relativ lange. Will man einen Dienst aufbauen, der „Ähnliche Produkte“ z.B. via API zur Verfügung stellt, lohnt es sich den Index aufzubauen und zu speichern. Bei einer neuen Anfrage kann man den Index laden und Ergebnisse anzeigen lassen. Das ist extrem schnell und perfekt für den Einsatz via API geeignet:
s.save('similar.ann')
Später kann man den Index folgendermaßen aufrufen:
features = 4
s = AnnoyIndex(features)
s.load('similar.ann')
Hinweis: „features“ steht für die Anzahl von Eigenschaften, die die Produkte haben. Das muss also angepasst werden, wenn mehr Eigenschaften verwendet werden.
Ein komplettes, allerdings recht abstraktes Beispiel, findest du auf github: spotify/annoy
Neben Annoy gibt es noch einige interessante Tools und Bibliotheken, die jeder Python-Entwickler mal anschauen sollte, wenn es um das Thema ANN oder KNN geht:
Spotify Annoy am Beispiel – Erklärung
Zuerst erstellen wir eine Liste mit 5 Produkten, die je 4 Eigenschaften haben, diese ist in „ps“ gespeichert. Hierbei steht jede Zahl für eine Eigenschaft. Das habe ich im Python-Quellcode im vorherigen Abschnitt bereits gemacht. So hat das Produkt #0 und #1 an erster Stelle die „1“ – das könnte z.B. die Anzahl der Räder des Produkts sein. In der vierten Eigenschaft unterscheiden sich die ersten drei Produkte offenbar (4,5,6). Die Produkte #3 und #4 scheinen komplett anders zu sein und kaum Übereinstimmungen zu haben. Anschließend wird der Index aufgebaut und kann dann abgefragt werden.
Die erste Abfrage:
s.get_nns_by_vector( [10,4,3,1], 2 , -1, include_distances=True)
Wir suchen also zwei ungefähr ähnliche Produkte in unserer Datenbank („ps“), welche zu den Eigenschaften „[10,4,3,1]“ passen.
Das Ergebnis:
([3, 4], [1.4142135381698608, 3.1622776985168457])
Das Produkt mit dem Index 3 in unserer Datenbank (Achtung, wir zählen ab 0) ist am ähnlichsten zu unserer Suchanfrage.
Ein weiterer Versuch:
s.get_nns_by_vector( [7,2,3,9], 2 , -1, include_distances=True)
Das Ergebnis:
([2, 4], [6.0, 6.244997978210449])
Auch das passt ganz gut. #2 hat mit unserer Suche die letzten drei Eigenschaften gemeinsam. #4 ist nicht exakt identisch in der ersten Eigenschaft, aber offenbar recht nah dran (7 und 10). Die drei weiteren Eigenschaften spielen hierbei auch eine Rolle. Man schaue sich beispielsweise die dritte Eigenschaft an (3 und 4), diese sind ebenfalls recht nah beieinander.
Was will ich damit sagen: Man kann solche Algorithmen recht gut nutzen, um ähnliche Produkte (oder auch ähnliche Texte) zu finden. Das ganze hat aber seine Tücken.
Euklidische Distanz und Ähnlichkeit
Wie nah sich zwei Produkte sind, kann einfach berechnet werden. In meinem Fall verwende ich den euklidischen Abstand (metric=“euclidean“). Auf Wikipedia findet man für einen n-Dimensionalen Raum folgende Gleichung:
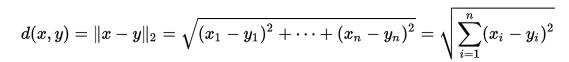
Diese Gleichung lässt sich auf unser letztes Beispiel anwenden:
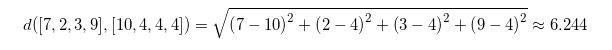
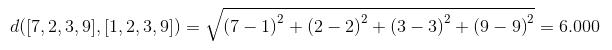
Man erkennt sofort, dass uns Spotify Annoy ebenfalls genau diese beiden Zahlen ausgegeben hat:
([2, 4], [6.0, 6.244997978210449])
Sie beschreiben die in dem Fall euklidische Distanz zwischen den beiden Vektoren. Je näher sich zwei Vektoren sind, desto ähnlicher sind sie sich.
Welche Berechnung verwendet wird, hängt von den Eigenschaften ab. Es stehen des Weiteren noch „angular“ sowie „manhatten“ zur Verfügung.
Spotify Annoy und Fernseher: Praxisbeispiel
Ich habe zu meinen Fernsehern in der Datenbank mehr als 30 Eigenschaften eingetragen – meist Zahlenwerte (1 = Ja, 0 = Nein), aber auch Texte sind dort zu finden (Hersteller = Samsung). Abseits davon gibt es auch Eigenschaften, wie das Gewicht oder die Größe in Zoll. Um Algorithmen, wie ANN/KNN verwenden zu können, muss man zusehen, dass die eigenen Daten ggf. standardisiert sind, wenn man ordentliche Ergebnisse will. Sehe ich den Hersteller als Eigenschaft, so muss ich irgendwie sagen:
| Eigenschaft | Wert |
|---|---|
| Samsung | 0 |
| LG | 1 |
| Sony | 2 |
| … | |
| Hisense | 11 |
Hier kann es aber schnell zu Probleme kommen. Angenommen ich will Alternativen für „LG-Fernseher“, so wird man wir vermutlich – nur auf Basis dieser einen Eigenschaft – „Samsung“ oder „Sony“ vorschlagen, weil 0 und 2 näher an 1 sind, als beispielsweise die 11 (Hisense). Das würde in dem Fall sogar Sinn machen – wer LG sucht, wird einen Samsung-Fernseher eher als Alternative ansehen, als einen Hisense-Fernseher.
Was ist aber, wenn die Hersteller-Daten folgendermaßen angelegt wurden:
| Eigenschaft | Wert |
|---|---|
| Samsung | 0 |
| Hisense | 1 |
| Sony | 2 |
| … | |
| LG | 11 |
Suche ich jetzt eine Alternative für LG wird mir allerhand vorgeschlagen, aber tendenziell eher nicht Samsung oder Sony. Die Distanz (je nachdem welche Art von Distanz gewählt wurde, Parameter „metric“) spielt hier eine große Rolle.
Was also machen? Hier wird jeder selbst eine Strategie finden müssen. Ich baue Cluster – Samsung, LG, Sony sind beispielsweise im Cluster 0, Hisense, Panasonic und Sharp in 5 und alle anderen in 10. So werden die Ergebnisse genauer.
Ein anderer interessanter Fall ist die Größe in Zoll. Hier
könnte man diese Zahl direkt verwenden:
32, 42, 50, 55, 65, 70, 75, 80
Allerdings – finde ich – dass als Alternative für einen 65 Zoll Fernseher, der 60 Zoll Fernseher besser ist als der 70 Zoll Fernseher. Würde ich diese Zahlen so als Eigenschaften verwenden, würden beide Alternativen gleich viel wert sein. Besser ist es – so meine Erfahrung für MEINEN Fall – z.B. mit x², x³ oder exp(x) zu arbeiten – dadurch ist der z.B. euklidische Abstand zwischen 50 und 55 kleiner als zwischen 55 und 60. Wer Lust hat, kann die Werte mal mittels x² oder x³ transformieren:
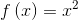
Mit der Formel folgt:
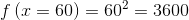
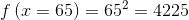
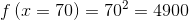
Rechnet man die Differenz zwischen den drei Werten aus, sieht man, dass zwischen dem 60 und 65 Zoll Fernseher eine kleinere Differenz ist (4225-3600 = 625), als zwischen dem 65 und 70 Zoll Fernseher (4900 – 4225 = 675). Es lohnt sich das mal selbst mit Spotify Annoy auszuprobieren.
Transformiert man eine Eigenschaft in der Form, kann es aber sein,
dass ihr Einfluss übermäßig wird bzw. stark dominiert. Das klassische Beispiel wären zwei Eigenschaften – Gewicht eines Menschen
zwischen 40-130 Kilogramm und irgendwelche Blutwerte, die im Bereich zwischen 2 und 3 sind. Bei der Auswahl eines passenden Nachbar, wird das Gewicht einen viel größeren Einfluss auf die Distanz haben als der Blutwert. Die Ergebnisse könnten in eine Richtung verfälscht werden, die eher suboptimal ist.
Das wäre so ein Punkt, wo man beide Eigenschaften standardisieren könnte, so dass beide Eigenschaften am Ende Zahlen zwischen 0 und 1 sind. In so einem Fall wäre die Gewichtung beider Faktoren identisch. Dieses Verhalten ist aber ggf. eben nicht gewollt. Da heißt es sich Gedanken über die eigenen Daten und Produkte machen. In meinem persönlichen Fall (Größe in Zoll) ist allerdings eine andere Gewichtung nötig wichtig – niemand der initial nach einem 65 Zoll Fernseher sucht, wird einen 32 Zoll Fernseher wollen, der exakt die gleichen Eigenschaften hat (sich aber nur in der Größe unterscheidet).
Im Netz findet man zu dem Thema durchaus viel Input, der empfehlenswert ist. Oft reichen schon wenig sinnvolle Transformationen der Daten und die Performance steigt: www.scholarpedia.org
Integration in eigene Software/Scripte
Bevor man Spotify Annoy für eigene Projekte wirklich verwenden kann, muss man im Endeffekt viel Vorarbeit leisten:
- Installation von Annoy auf dem eigenen Server
- Eigenschaften aller Produkte aggregieren
- Eigenschaften normalisieren, standardisieren, anpassen oder was sonst nötig ist
- Spotify Annoy-Index aufbauen und speichern
Wie ihr die Daten konkret an Annoy schickt, bleibt euch überlassen und ist je nach Softwarearchitektur und eigenen Möglichkeiten natürlich auf vielfache Weise möglich.
Ich nutze im Fall der Fernseher-Seite Laravel als PHP Framework und verwende Artisan Commands (CLI), um beispielsweise Daten (als JSON) an das python-Script zu schicken. Dann wird der Index aufgebaut und abgespeichert. Anschließend nutze ich ein anderes Artisan Command, mit dem ich quasi die Daten eines jeden Produktes so aufbereite (normalisieren, standardisieren, …), wie ich es auch beim Aufbau des Index gemacht habe. Das ist ein Schritt der immer zu bedenken ist. Wenn ihr beim „Training“ die Hersteller in Gruppen geclustered habt, dann müsst ihr das auch beim aktuellen Produkt machen. Es sollte ein Vektor entstehen, den man an den Index schicken kann. Als Antwort bekommt man dann die X passendsten Produkte. Diese Produkte speichere ich als JSON-String in die Datenbank, so dass ich kein API benötige, um ähnliche Produkte zu bestimmen. In meinem Fall macht mein Vorgehen am meisten Sinn. Bei dir kann das anders aussehen.
Wer sich für Code interessiert, findet im Folgenden einige Insights – diese werden euch aber nicht so viel bringen, weil solche Lösungen sehr speziell sind und nur schwer auf andere Seiten/Produkte übertragen werden können.
Zuerst werden alle relevanten Produkte aus der Datenbank gelesen und dem Objekt/Klasse zur Verfügung gestellt.
private function getProducts(int $category)
{
$products = \App\Product::where('category_id', $category)
->where('exclude_from_website', 0)
->where('exclude_from_sitemap', 0)
->where('metarobots', 'index, follow')
->where(function ($query) {
$query->where('price_new', '>', 0)
->orWhere('price_new_thirdparty', '>', 0);
})
->orderBy('id', 'desc')
->get();
$this->productlist = $products;
}
Anschließend wird für jedes Produkt dessen benötigte Eigenschaften ausgelesen und die Features extrahiert.
Auf Basis aller verfügbaren Werte pro Eigenschaft, werden diese dann normalisiert und standardisiert. Hierfür
existiert eine config-Datei, über die ich kontrollieren kann, welche Eigenschaften welche Rolle spielen, wie verarbeitet werden und wie gewichtet werden.
private function makeNormalizationDataset(int $category)
{
$featureLists = [];
$productRepository = new \App\Repository\ProductRepository();
foreach ($this->productlist as $product) {
$productData = $productRepository->getProductData($product);
$featureLists[] = \App\Machinelearning\FeaturelistGenerator::extractFeatures($productData);
}
$this->featureNormalizer = \App\Machinelearning\FeaturelistGenerator::makeNormalizedFeatures($featureLists, $category);
}
Hier ist wohl die Methode „makeNormalizedFeatures“ von Interesse.
public static function makeNormalizedFeatures(array $featureLists, int $category_id): array
{
$featureNormalizer = [];
foreach ($featureLists as $featureList) {
foreach ($featureList as $featureName => $feature) {
if ($featureName == 'id') {
continue;
}
if (!isset($featureNormalizer[$featureName])) {
$featureNormalizer[$featureName] = [];
} elseif (isset($featureNormalizer[$featureName]) && !in_array($feature, $featureNormalizer[$featureName])) {
if (is_null($feature)) {
continue;
}
$featureNormalizer[$featureName][] = $feature;
}
}
}
$config = config('machinelearning');
$settings = $config[$category_id]['settings'] ?? [];
foreach ($featureNormalizer as $featureName => $featurePossibilities) {
if (isset($settings[$featureName])) {
foreach ($settings[$featureName] as $runs) {
$featureNormalizer[$featureName] = self::run($runs, $featurePossibilities);
$featurePossibilities = $featureNormalizer[$featureName];
}
}
}
return $featureNormalizer;
}
Jetzt kann ich alle Produkt bzw. deren Eigenschaften „übersetzen“ und an Annoy zum Aufbauen eines Index schicken. Dabei werden die „Rohdaten“ des Produkts gegen ein Array aus den gleichen – aber verarbeiteten (norm., stand., …) Daten geprüft und entsprechend angepasst und anschließend als JSON-String gespeichert.
private function trainMLSpotifyAnnoy(int $category, int $trees)
{
$productFeatures = [];
$productRepository = new \App\Repository\ProductRepository();
foreach ($this->productlist as $product) {
$productData = $productRepository->getProductData($product);
$featureList = \App\Machinelearning\FeaturelistGenerator::extractFeatures($productData);
$featureListNorm = \App\Machinelearning\FeaturelistGenerator::normalizeFeatures($this->featureNormalizer, $featureList, $category);
$productFeatures[$product->id] = array_values($featureListNorm);
}
$train_data = json_encode($productFeatures);
$predictPath = base_path('machinelearning');
$command = 'python ' . $predictPath . '/trainer.py \'' . $category . '\' \'' . $train_data . '\' ' . $trees;
$exec = system($command);
Das Array, das im Script in einen JSON-String umgewandelt wird, besteht im Grunde aus der Liste von Produkten und deren Eigenschaften, wobei der Key des Arrays die Produkt ID darstellt. Das ist am Ende das, was Spotify Annoy ausgeben wird.
Der JSON-String geht dann an die folgenden Datei und generiert damit den Index, der abgespeichert wird.
#!/usr/bin/env python
# coding: utf8
import json
import os
import random
import sys
from annoy import AnnoyIndex
category = sys.argv[1]
jsonstring = sys.argv[2]
base_path = os.path.abspath(
os.path.dirname(
sys.modules['__main__'].__file__
)
)
jsondecoded = json.loads(jsonstring)
trainableItems = jsondecoded.keys()
for item in jsondecoded:
testitem = item
break
featureNr = len(jsondecoded[testitem])
trainableFeatures = []
for item in trainableItems:
trainableFeatures.append([item, jsondecoded[item]])
t = AnnoyIndex(featureNr, metric="euclidean")
for product in trainableFeatures:
t.add_item(int(product[0]), product[1])
t.build(int(sys.argv[3]))
t.save(base_path + '/annoy_cat_' + category + '.model')
Jetzt können wir ein Produkt aus der Datenbank nehmen, die Eigenschaften extrahieren, sie mit unserem Normalisierer verarbeiten und an Annoy schicken:
private function getSimilarItemsForEveryProduct(int $category, int $nsearches)
{
$productRepository = new \App\Repository\ProductRepository();
foreach ($this->productlist as $product) {
$similarItems = [];
$productFeatures = [];
$productData = $productRepository->getProductData($product);
$featureList = \App\Machinelearning\FeaturelistGenerator::extractFeatures($productData);
$featureListNorm = \App\Machinelearning\FeaturelistGenerator::normalizeFeatures($this->featureNormalizer, $featureList, $category);
$productFeatures[$product->id] = array_values($featureListNorm);
$test_data = json_encode($productFeatures);
$predictPath = base_path('machinelearning');
$command = 'python ' . $predictPath . '/predict.py \'' . $category . '\' \'' . $test_data . '\' ' . $nsearches;
$response = exec($command);
preg_match_all('~\\(\[(.*?)\], \[(.*?)\]\)~s', $response, $data);
if (isset($data[1][0])) {
$prodGets = explode(", ", $data[1][0]); // similar items (their product id)
$prodDist = explode(", ", $data[2][0]); // distance between prod and every item
}
// Only products with 90% of the max distance qualify
$minDist = max($prodDist) * 0.90;
$productsFound = 0;
foreach ($prodGets as $k => $id) {
$findProd = \App\Product::find($id);
if (!is_null($findProd) && $prodDist[$k] <= $minDist && $product->id != $findProd->id) {
$similarItems[] = $findProd->id;
}
}
$similarItems = json_encode($similarItems);
$product->similar_items = $similarItems;
$product->save();
In dem Moment sind die ähnlichen Produkte in der Datenbank und können von dort aus im Frontend angezeigt werden.
Der Vollständigkeit halber findet man noch im Folgenden das python-Script, das ähnliche Produkte findet:
#!/usr/bin/env python
# coding: utf8
import json
import os
import random
import sys
from annoy import AnnoyIndex
category = sys.argv[1]
jsonstring = sys.argv[2]
base_path = os.path.abspath(
os.path.dirname(
sys.modules['__main__'].__file__
)
)
jsondecoded = json.loads(jsonstring)
trainableItems = jsondecoded.keys()
for item in jsondecoded:
testitem = item
break
featureNr = len(jsondecoded[testitem])
# Create empty annoy index
t = AnnoyIndex(
featureNr,
metric="euclidean"
)
t.load(base_path + '/annoy_cat_' + category + '.model')
print(t.get_nns_by_vector( jsondecoded[testitem], 12, int(sys.argv[3]), include_distances=True ))
Ich hab den Code relativ schnell programmiert. In Zukunft muss ich noch zusehen, dass er leserlicher wird und vor allem die foreach() { foreach() { verschwinden. Man hat ja sonst nichts fürs Refactoring 😛 Zeit ist aber kostbar, daher kommt das erst in naher Zukunft! Gleiches gilt für die python-Scripte. Kommentare und PHP Doc wurden zum Großteil entfernt, damit sie den Leser nicht erschlagen. Außerdem ist der Code nicht vollständig, er soll im Grunde nur demonstrieren, was man alles machen muss, um überhaupt so etwas wie Spotify Annoy nutzen zu können.
Wer richtig viele Produkte hat, sollte außerdem vermeiden, einfach einen großen JSON-String an Python zu schicken. Spotify Annoy beherrscht das Hinzufügen von weiteren Vektoren zum Index. Das sollte man in solchen Fällen nutzen.
In Summe sieht man ganz gut, dass so etwas nicht an einem Tag runterprogrammiert werden kann und durchaus großer Aufwand ist.
Der Aufwand lohnt sich…
In meinem Fall verwende ich die Ergebnisse an zwei Positionen der Seite
- Fernseher Kaufberatung
- Datenblätter der Geräte
Das Ganze ist auf den folgenden Screenshots zu sehen:
Datenblatt

Kaufberater
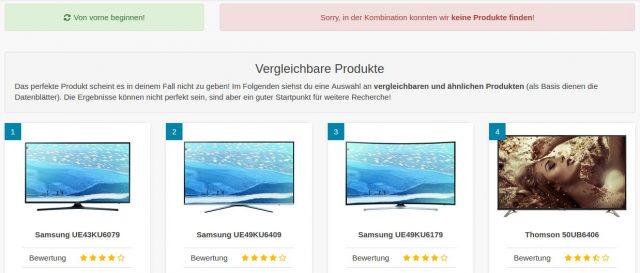
Im Fall der Kaufberater, ist es bei mir so, dass viele den perfekten Fernseher einfach nicht finden – weil es ihn nicht gibt. Ein 65 Zoll Fernseher für 500 Euro und OLED ist eben nicht möglich. Solchen Suchanfragen zeigte ich bisher NICHTS an – außer einer Meldung, dass es keine Produkte gibt. Seit kurzem werden (nach min. 3 beantworteten Fragen) in so einem Fall die ähnlichsten Produkte angezeigt.
Dieses Feature wird super angenommen und bisher kam nur positives Feedback. Ich muss an der Stelle trotzdem noch an der Normalisierung und Standardisierung der Daten arbeiten, damit die Ergebnisse noch besser werden. Vor allem die Gewichtung bestimmter Parameter eines Gerätes wird in den folgenden Versionen der TV-Seite verbessert und optimiert.
Konkret – bringt es mehr Geld?
Ja, ich tracke recht penibel alles, was auf der Seite passiert und richte meine Aktionen danach aus. Was ich sagen kann: Vor allem durch die Kaufberater ist die Klickconversion (auf externe Shops) fast verdoppelt worden. Das hat Auswirkung auf die Klickconversionrate der gesamten Seite. Konkrete Zahlen werde ich nicht preisgeben – die Konkurrenz liest ja mit 😉
Vielleicht konnte ich den ein oder anderen ermutigen, sich mit dem Thema für das eigene Projekt auseinander zu setzen. Der Artikel versteht sich natürlich auch als Promo für meine Wenigkeit als Entwickler. Ich freue mich immer über experimentierfreudige Kunden, die Dinge machen, die man nicht unbedingt von der Stange bekommt, um hervorzustechen 😉


