Was ist Numerai bzw. NMR?
Numerai ist ein Hedgefond, dessen Anlage/Investmentstrategien auf Voraussagen basieren, die von Machine Learning-Experten erstellt werden. Jeder Teilnehmer kann pro Woche maximal drei Modelle einreichen und nimmt damit am Wettbewerb teil. Kurz gesagt bekommt man von Numerai Finanzmarktdaten und soll die kommenden Wochen/Tage voraussagen. Basierend auf einem Metamodel, das aus aus den besten Modellen der Experten besteht, wird dann prognostiziert und geschaut, wie dieses Metamodel in der „richtigen Welt“ performed.
Zu Beginn konnte das Startup 6 Millionen US-Dollar als Startkapital einsammeln. Das initiale Volumen des Hedgefond betrug 1 Millionen US-Dollar und wurde von Richard Craib, dem CEO/Gründer von Numerai, gestellt.
Funktionsweise und Details findet man im Whitepaper.
Gibt es etwas zu gewinnen?
Irgendeinen Anreiz muss es geben. Was es zu gewinnen gibt, wird ab und an angepasst. Aktuell bekommen die 100 besten Modelle US-Dollar und Numeraire (kurz NMR). Für den ersten Platz gibt es 400 US-Dollar und 211 NMR. Letzteres hat Numerai (weiterführende Informationen im Whitepaper oder hier auf medium.com) als Coin (vergleichbar mit Bitcoin oder Ethereum) eingeführt, mit dem Teilnehmer auf ihre eigenen Voraussagen setzen können. Ist die eigene Voraussage solide, kann man US-Dollar gewinnen (je nach Menge eingesetzter NMR sowie dem eigenen Vertrauen in die Voraussage).
Ist sie schlecht, werden die eingesetzten NMR zerstört. Man sollte sich also als Teilnehmer überlegen, ob man Overfitting der eigenen Modelle betreibt, damit vielleicht dann in den Test/Trainingsdaten gut aussieht, aber im richtigen Leben eben nichts voraussagen kann.
Im Grunde gibt es also zwei Mechanismen etwas zu gewinnen:
- die 100 besten Modelle (in Summe wöchentlich ~ 3770 US Dollar und 2000 NMR)
- „Wette“ auf das eigene Modell (in Summe wöchentlich 6000 US-Dollar)
Aktuell kann man den NMR-Coin auf diversen Börsen handeln – beispielsweise Bittrix. Dort ist er jetzt (25. Oktober 2017) 12,36 $ Wert.
Wer also jetzt den ersten Platz machen würde, würde 400 US-Dollar und 211 NMR-Coins bekommen – diese könnte er direkt verkaufen und würde dafür aktuell 2607,96 US-Dollar bekommen. In Summe also gerundet 3000 US-Dollar, die man wöchentlich gewinnen kann. Je nach Kursentwicklung kann das aber auch weniger oder deutlich mehr sein. Wer dann noch klug beim Staking vorgeht, kann die Payouts erhöhen.
Die aktuelle Payout-Struktur findet man in Google Drive.
Wichtig: Wer wie viel bekommt, zeigt sich erst, wenn die eigenen Modelle vier Wochen nach Einreichen gegen den echten Markt geprüft werden. Wer dann eine gute Performance abliefert, gewinnt.
Wie kann ich teilnehmen?
Im Grunde meldest du dich auf numer.ai an und kannst direkt Daten herunterladen. Es lohnt sich die Regeln zu lesen. Die Teilnahme ist kostenlos. Es kostet aber Zeit wirklich solide und gute Modelle zu errechnen.
Dich erwartet dann das folgende Dashboard:
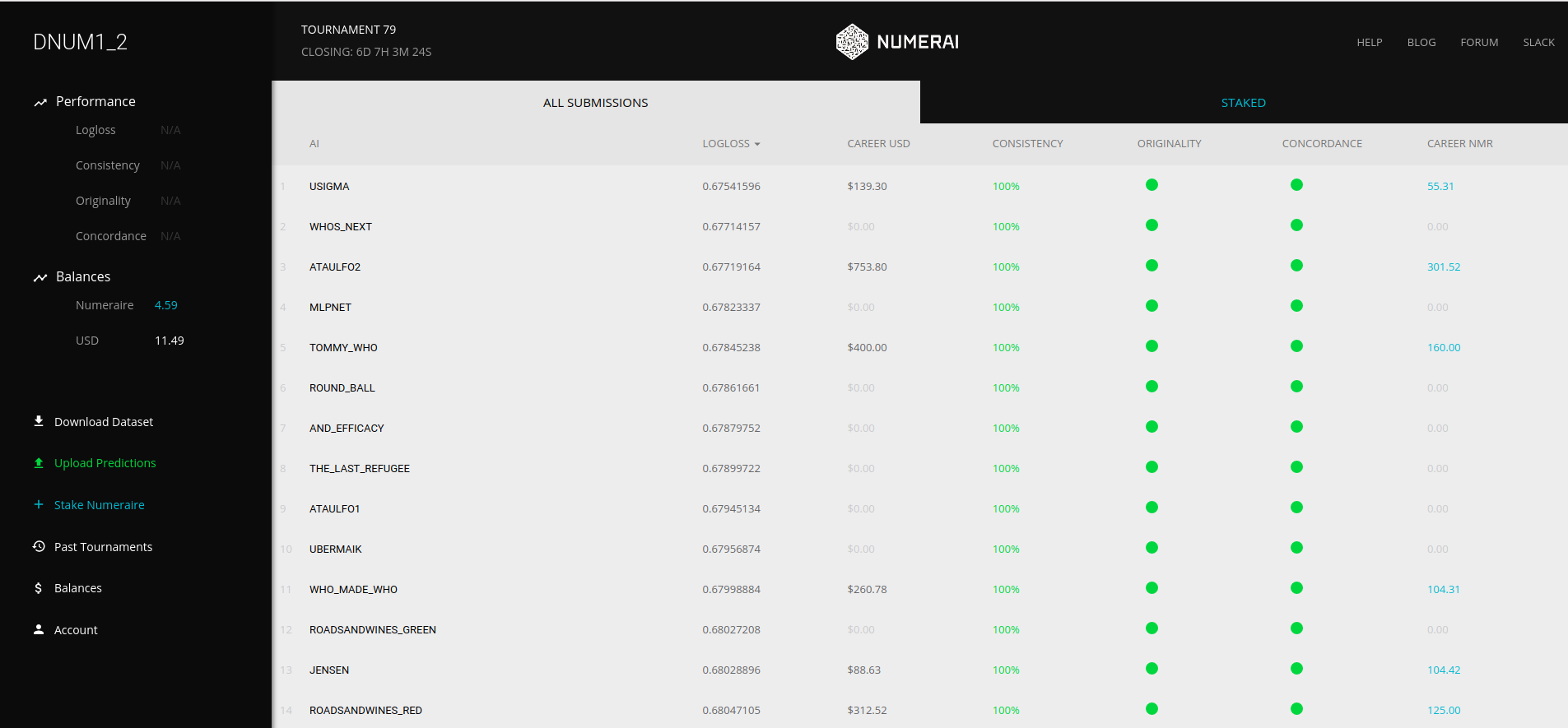
Von numer.ai zur Verfügung gestellte Daten
Man kann ein Paket herunterladen, in dem simpler Democode zu finden ist und die beiden wichtigsten Dateien. numerai_tournament_data.csv sowie numerai_training_data.csv. Die Dateien bestehen aus 54 Spalten, wovon 50 Eigenschaften (im Folgenden Features) sind und eine Spalten das „Ziel“ (im Folgenden Target oder Class) sind. Die restlichen drei Spalten sind pro Zeile eine eindeutige ID, eine „ERA“ Angabe sowie die Art der Zeile.
Die ID brauchen wir später bei der Generierung der Ergebnisdatei. „ERA“ stellt vermutlich (!?) irgendeinen zeitlichen Wert dar und data_type kann „train“, „validation“ oder „live“ sein.
Die Struktur sieht folgendermaßen aus:
Konkrete Zahlenwerte sowie einige kurze Erläuterungen gibt es in den beiden nächsten Abschnitten.
numerai_training_data.csv
In dieser Datei findest du die Trainingsdatensätze. Hiermit trainierst du dein Modell. Du hast 50 Features und eine binäre Target (1 oder 0). Die für diesen Artikel zugrundeliegende Datei kommt aus dem 79. Wettbewerb und umfasst 535713 Zeilen und die Spalte „data_type“ ist immer „train“. Die ersten 5 davon siehst du im Folgenden:
numerai_tournament_data.csv
Auch hier hast du deine Metadaten, 50 Features und eine Target (1 oder 0). Diese Datei umfasst allerdings „validation“, „test“ und „live“ als Datentypen.
- „validation“-Daten können dazu verwendet werden, dein Modell zu testen. Die steht hier die Target auch zur Verfügung.
- „test“-Daten sind vermutlich Daten, deren Target NUR numerai kennt. So können sie vermutlich eingereichte Modelle bewerten.
- „live“-Daten sind die Daten, deren Ergebnis niemand kennt und die sich erst im Laufe der kommenden vier Wochen zeigen werden.
Ein kurzer Blick in die Daten:
Allgemeine Struktur der Features
Du hast sicher schon gesehen, dass die Features alles Zahlen zwischen 0 und 1 sind und vielleicht fragst du dich, was das mit Finanzmarktdaten zu tun hat. Diese Datensätze sind natürlich anonymisiert und verschlüsselt. Keiner weiß, was jede Zahl wirklich bedeutet oder wie wichtig sie ist. Man hat also keine Informationen zu diesen Datensätzen, man weiß nicht, von wo sie kommen oder was sie genau bedeuten.
Visualisierung der Trainingsdaten
Es lohnt sich diese große Menge an Daten zu visualisieren. Wie oben erwähnt, liegen alle Werte zwischen 0 und 1. Im Detail wäre interessant, wie die Verteilung der Werte pro Feature aussieht, was die Mittelwerte sind und ob es Ausreißer gibt. Machen wir das doch mal:
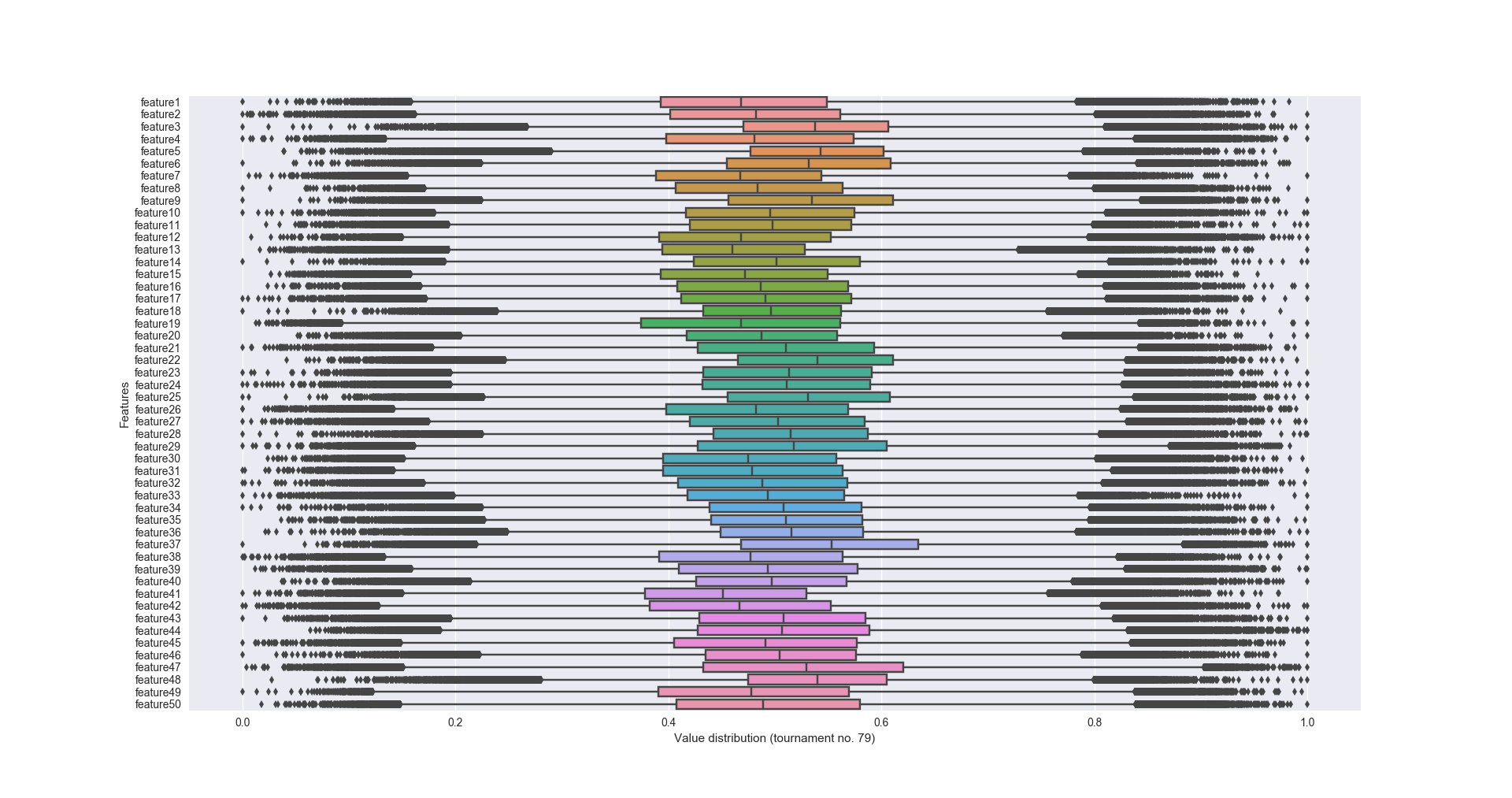
Auch die Anzahl von Zeilen pro ERA lässt sich schön anzeigen. Im Grunde sieht man aber, dass für jedes Feature die Anzahl von Zeilen mit target = 0 bzw. = 1 in etwa gleich bei ~ 3000 ist. Die Trainingssätze sind also recht gut und gleichmäßig verteilt. Interessant ist natürlich auch die Anzahl an sich. Wir wissen nichts zu ERAs, aber es liegt nahe, dass sie in irgendeiner Form eine zeitliche Angabe sind. Neue Daten kommen jede Woche raus… also gibt es pro Woche etwa 6000 Datenpunkte. Wenn die verschlüsselten Daten einen zeitlichen Verlauf darstellen, dann müsste dieser hoch aufgelöst sein.
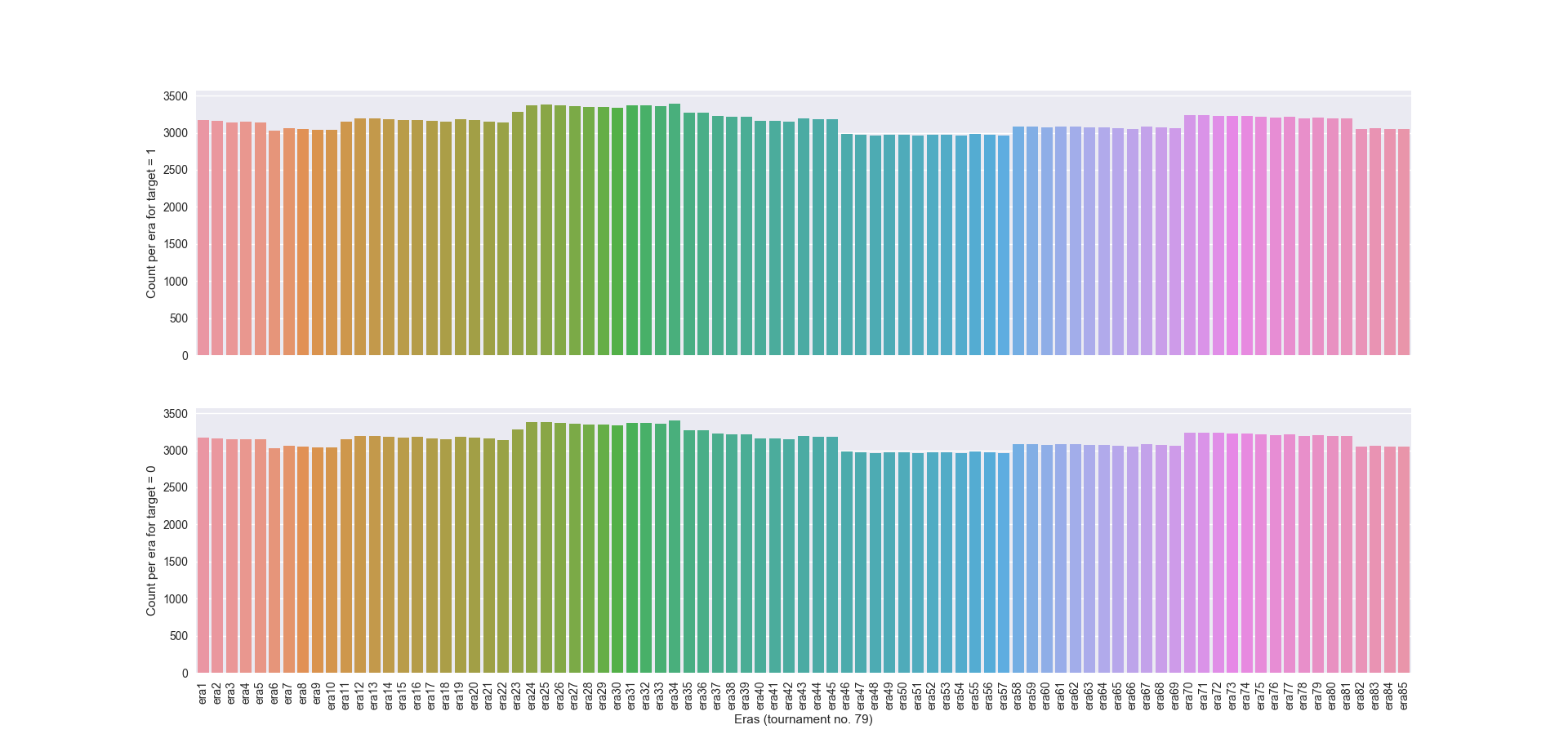
Hinweis: Zur Erstellung der Diagramme habe ich die Python-Bibliothek „seaborn“ verwendet. Die Handhabung ist einfach und es lohnt sich da mal reinzuschauen.
Als Aufgabe könnten Interessierte das gleiche nur mit den Validierungs- und Testdaten machen. Vielleicht gibt es hier ja Diskrepanzen in der Verteilung der Werte.
Trainieren, hochladen, fertig.
Einfach nur irgendein Modell zusammentrainieren wird – so viel kann ich verraten – nicht funktionieren. Dein Modell muss eine Ergebnisdatei generieren, die für jede ID im Tournament-Datensatz die Wahrscheinlichkeit (Probability) für das Eintreten von Target „1“ angibt. Diese Datei kannst du dann hochladen und anschließend wird sie bewertet. Es gibt einige Kriterien, die man bestehen muss, um am Wettbewerb teilnehmen zu können. Ansonsten gilt die eigene Prognose eben als schlecht.
- Logarithmischer Verlust
- Konsistenz
- Originalität des Modells
- Konkordanz (Concordance)
Wie sich diese Metriken berechnen, kann man im Grunde direkt bei numer.ai erfahren. Der ein oder andere hat ebenfalls bereits eine kurze Übersicht zu allen vier Punkten geschrieben.
Wir werden uns im Folgenden auf Konsistenz und den logarithmischen Verlust (kurz Log loss) konzentrieren. Beide Werte sind mit wenig Aufwand selbst berechenbar. Wer Lust und Laune hat, kann auch die beiden anderen Metriken selbst berechnen. Quellcode dazu gibt es bei numerai im verlinkten github-Account.
Problembeschreibung – „simpeles“ Klassifizierungsproblem
Das hier dargestellte Problem ist relativ simpel. Man hat 50 Eigenschaften und soll diese „klassifizieren“. Entweder die 50 Eigenschaften resultieren in der Klasse 1 oder eben in der Klasse 0. Hierbei handelt es sich um ein binäre Klassifikation – es gibt nur zwei Klassen. Analoge Problemstellungen sind z.B. Erkennung von Spam (Ist die E-Mail Spam? Ist die E-Mail kein Spam) oder die Erkennung von Sprache (ist es deutsch, englisch, polnisch, …). Letzteres wäre dann keine binäre Klassifikation – es gibt mehr als zwei potentielle Klassen.
Lohnenswerte Bibliotheken für die Challenge
Viele Wege führen nach Rom. Wir nehmen ganz klassische Frameworks, die jeder in diesem Bereich schon mal gehört hat. Eine kurze Einführung samt Code gibt es ebenfalls.
pandas
Pandas ist ein ausgezeichnetes Framework/Toolkit um z.B. CSV-Dateien einzulesen, zu verarbeiten, anzupassen und wieder als Datei abzuspeichern. Es gibt unheimlich viele Methoden, die einem das Leben erleichtern. Eine simple Demonstration wichtiger Methoden.
numpy
Numpy ist ein Toolkit/Framework, dass wissenschaftliches Rechnen – vor allem mit komplexen Arrays enorm vereinfacht. Im Bereich Machine Learning wird es dir immer wieder begegnen. Man kann damit ganz wunderbar normale Pythonlisten in Numpy Arrays umwandeln und hat damit Zugriff auf ein enormes API zu Berechnung diverser Werte. Als simples Beispiel:
sklearn
Sklearn ist vermutlich DAS Open Source Tool, das man verwendet, wenn man mit Machine Learning anfängt. Es bietet diverse sehr solide und schnelle Algorithmen, die sich gut für Klassifikations- oder Regressionsprobleme eigenen. Auch das Preprocessing und Datenanalyse fallen damit sehr einfach. Parallel gibt es Möglichkeiten vollautomatisch Parameter von Modellen zu optimieren oder Methoden für das Feature Engineering (oder Feature Selection). Da wir später mit sklearn arbeiten, verzichte ich auf ein Beispiel. Das API ist ausgezeichnet dokumentiert.
Hinweis: Es gibt natürlich noch eine Vielzahl anderer Frameworks – diese werden wir erstmal nicht verwenden. Im Kapitel Optimierung wird das ein oder andere erwähnt, das du dir anschauen solltest.
Problemlösung – Schritt für Schritt am Script entlang
Im folgenden werden wir zusammen ein Python-Script programmieren, mit dem man diese Challenge angehen könnte. Es dient lediglich der Demonstration, man wird sehen, was man mit pandas, numpy und sklearn so alles anstellen kann. Ich werden den Quellcode stückchenweise vorstellen und kommentieren. Ansonsten ist der Quellcode dann auch auf github.com zu finden. Jeder der Lust hat, kann ihn herunterladen und anpassen.
Ich kann vorwegnehmen, dass in einer so simplen Variante damit nichts zu gewinnen ist. Da wird man sich noch deutlich mehr Gedanken machen müssen. Ich wäre ja auch verrückt, Dinge zu verraten, für die ich teilweise Wochen gebraucht habe 😉
Scipt-Header
Im Kopf der Datei siehst du erstmal nicht viel, außer einer kurzen Auszeichnung, dass es sich um ein Python-Script handelt und welche Bibliotheken und Pakete wir verwenden. Ich gehe hier nicht durch, wie man Pakete installiert. Das wirst du selbst rausfinden.
Optionen des Scripts
Im oberen Teil der Datei findest du einige Einstellmöglichkeiten. Diese sollst du erstmal so hinnehmen. Sie werden später näher erläutert. Erst einmal folgt nur eine kurze Übersicht dieser Optionen, mit denen du natürlich auch die Performance deines Modells auf eine gewisse Art und Weise beeinflussen kannst.
- feature_cols_to_keep: Hier hast du die Möglichkeit, anfangend bei 1 und mit 50 endent, zu bestimmen, welche Features beim Training verwendet werden sollen.
- eras_to_exclude_from_trainingset: Mit dieser Liste kannst du bestimmte ERAs vom Trainingssatz ausschließen.
- kept_eras_in_trainingset: Umgekehrt kannst du auch ERAs nennen, die nur verwendet werden sollen.
- combine_training_and_val_data_into_one_trainingset: Du könntest auch die Validierungsdaten mit in den Trainingssatz aufnehmen – numerai empfiehlt das ausdrücklich nicht. Ich will mich dem anschließen.
- save_good_models: Hast du ein gutes Modell gefunden und trainiert, kannst du hier bestimmen, ob es auf der HDD abgespeichert werden soll.
- save_result_file: Das gleiche gilt für die Ergebnisdatei, die du bei numerai hochladen wirst.
- cv_number: Wenn Cross Validation verwendet wird, kannst du angeben wie oft dein Modell getestet wird.
- test_size_for_train_test_split: Hiermit bestimmst du die wie viel vom Trainingsdatensatz als Testdatensatz verwendet werden soll.
Arbeitsordner und schnelle Prüfung der Daten auf Vorhandensein
Hier siehst du, wie relevante Ordner und Dateien auf Vorhandensein geprüft werden. Sind die beiden Dateien „numerai_tournament_data.csv“ und „numerai_training_data.csv“ nicht vorhanden, braucht es hier gar nicht weitergehen. Außerdem wird im letzte Schritt geprüft ob parallel ERAs aus- und eingeschlossen werden. Das macht wenig Sinn – verwende nur eine dieser Optionen.
Dateien einlesen
Jetzt werden beide Dateien mit Hilfe von pandas eingelesen. Du siehst hier direkt, dass ich die Tournament-Daten in Validation und Tournament/Live-Daten unterteile und vor allem, wie einfach das mit Pandas ist.
Schnelle Übersicht zu den Rohdaten
Mit den paar Zeilen gebe ich auf die Schnelle die wichtigsten Eigenschaften zu den Datensätzen aus:
Data summary after raw import:
Tournament data: 348831 rows 54 columns
Training data: 535713 rows 54 columns
Validation data: 73865 rows 54 columns
Erste Überlegung (Data Selection)
Zusammenlegen von offiziellen Trainings- und Validierungsdaten
Im ersten Schritt siehst du, dass ich in no_feature_cols nur die Spalten der Dateien definiere, die keine Features sind. Anschließend hole ich mir aus den gesamten Tournament-Daten pro Zeile die ID sowie die Features. Diese werden wir später für das Generieren unserer Ergebnisdatei brauchen. Die Features brauchen wir natürlich, um mit unserem Modell dann zu schauen, ob 1 oder 0 rauskommt.
Die erste Option kommt hier zum Zug – nämlich das Zusammenlegen von offiziellen Trainings- und Validierungsdaten. Kann man machen, wird aber von numer.ai nicht empfohlen:
„The test set, validation set and live set should be treated as hold out sets. We recommend you do not train on the validation data even though you have the targets. If you create features using unsupervised learning be careful not to include the validation set, test set, or live set. Be careful of unsupervised learning generally.“
Ich hab dir die Option implementiert, dann kannst du damit etwas rumspielen.
Ausschließen/Einschließen bestimmter Eras könnte Ergebnisse verbessern
Hierfür gilt das gleiche. Die beiden gezeigten Codeabschnitte erlauben es bestimmte ERAs explizit vom Training auszuschließen. Umgekehrt ist es auch möglich NUR bestimmte ERAs für das Training zu verwenden. Hier musst du vorsichtig sein. Zum einen wird das Ausschließen von ERAs mit Sicherheit dafür sorgen, dass dein Modell nicht gut generalisieren kann und im realen Leben schlechte Prognosen abgibt.
Außerdem bräuchtest du hier irgendwie einen Weg, um herauszufinden, welche ERAs, man ggf. ausschließen/einschließen sollte. Möglichkeiten gibt es so einige. Hier werde ich dir natürlich nicht helfen.
Aufteilen in Features und Targets
Anschließend müssen wir die „DataFrame“ genannten Strukturen in Features und Targets zerlegen. Das ist nötig, weil die meisten Algorithmen als Parameter den Input (Features) und den Output (Targets) als einzelne Parameter der jeweiligen Methoden benötigen.
Zweite Überlegung (Feature Selection)
Ausschluss bestimmter Features könnte Ergebnisse verbessern
Je mehr du dich mit dem Thema beschäftigst, desto eher kommst du an einen Punkt, wo du die Features an sich untersuchen willst. Dafür gibt es diverse Möglichkeiten – an dieser Stelle werden eben nur die Features gewählt, die du im Vorfeld in den Optionen ausgewählt hast. Auch hier musst du aufpassen – es kann passieren, dass deine Auswahl die Performance bzw. die Fähigkeit deines Modells auch in unbekannten Situationen (also mit bisher ungesehenen Datensätzen) gute Ergebnisse zu liefern STARK einschränkt.
Vergiss aber NIE – wenn du Features aus dem Training ausschließt – das auch für die Validierungs- und Tournamentdaten zu machen.
Dritte Überlegung (Feature Engineering)
Eigene Features verwenden
Feature Engineering ist ebenfalls ein Thema, mit dem man sich beschäftigen sollte. Hier kann man vor allem was rausholen, wenn man noch irgendwelche Metainformationen hat. Das ist bei uns aber nicht der Fall. Zumindest ich hab hier – auf die Schnelle – keine Erfolge vorzuweisen. Ich kenne aber Leute, die Feature Engineering betreiben und damit Erfolg haben.
Auch hier gibt es im übrigen Methoden, um aus den 50 Features beispielsweise 255 zu machen, die viel feiner sind.
Das passende Stichwort wäre hier beispielsweise PCA. Dazu werde ich später sicherlich auch noch ein Wort verlieren. Es soll erstmal nicht das Thema sein.
Ich habe dir aber trotzdem eine simple Lamda-Funktion implementiet, mit der ein Feature generiert wird, damit du eine bessere Vorstellung hast. Das ganze funktioniert so: Für jede Zeile wird der Wert von feature1 mit dem Wert von feature2 multipliziert und potenziert (x²).
Auch hier siehst du: wenn du Feature Engineering betreibst, musst du es auf alle verwendeten Datensätze anwenden.
Tipp von mir: Wir haben es hier mit stark verschlüsselten Finanzdaten – vemutlich aus dem US-Bereich – zu tun. Die einzelnen ERAs könnten Zeiträume darstellen. Es wäre von Interesse ggf. die Daten diverser Aktienindices als Features mit einzubeziehen (Absoluter Wert, Differentialquotient in bestimmten Zeiträumen, …). Denkt mal drüber nach. Ich würde mir ja den S&P500 anschauen!
Vorbereitung der Rohdaten (Preprocessing)
Nun gibt es wieder einen Zwischenbericht zum aktuellen Trainingsatz. Anschließend werden die reinen Werte der Features für alle Datensätze, die relevant sind, geholt und ins so genannte Preprocessing geschickt – sie werden dort standardisiert/vereinheitlicht. Ich nutze hier eine sklearn Pipeline, die es erlaubt mehrere Transformationen hintereinander zu schalten.
Preprocessing ist ein durchaus komplexes Thema. Daher schau mal hier auf die Erläuterungen von sklearn.
An dieser Stelle wäre es im übrigen möglich neben dem Standardisieren auch Feature Selection oder Engineering zu betreiben, in dem man PCA (Principal Component Analysis) als letzte Komponente der Pipeline schaltet. Das könnte etwa so aussehen:
Hier gibt es noch weitaus mehr Möglichkeiten. PCA ist mittlerweile nicht mehr so extrem gut und man kann damit nur sehr wenig rausholen. Als noch vor einigen Monaten die alten Datensätze mit 20 Features verwendet wurden, sah das noch anders aus. Da konnte man mit PCA(n_components=11) ganz gute Ergebnisse erzielen – die 20 Features wurden also auf 11 komplett neue runtergebrochen.
Optional: Trainingsdaten in zwei Datenpakete (Train/Test) aufteilen
Das Anlegen von eigenen Test-Daten ist eine Standardprozedur und ein MUSS. In unserem Fall ist es allerdings nicht unbedingt nötig, weil wir extra Validierungsdaten von numerai gestellt bekommen haben. Diese würden den Zweck erfüllen. Trotzdem demonstriere ich, wie einfach das mit sklearn ist.
Du siehst, wie unser ursprünglicher Trainingsdatensatz in zwei Teile zerlegt wird. Zum einen ein „neuer“ Trainingssatz und ein „neuer“ Testsatz. Die Feature/Target-Paare werde in einzelne Variablen gespeichert und können direkt weiterverwendet werden. Über den Parameter test_size kannst du bestimmen, wie groß der Testdatensatz sein soll. 25 – 33% sind ganz gute Werte. In den Optionen zu Beginn der Datei ist 25% als Standardwert eingetragen.
Machine Learning: Trainieren des Models
Jetzt kommt das, was alle als Machine Learning bezeichnen – und du siehst, es ist nicht viel.
Ich verwende einen sehr einfachen Klassifizierungsalgorithmus namens „ExtraTreesClassifier“ mit einigen Parametern, die als Ausgangsbasis dienen sollen. Diese Parameter sind enorm wichtig. Sie bestimmen am Ende, wie gut dein Modell wird. Entsprechend wichtig wird es sein, hier die perfekten Werte zu finden. Aber auch dazu gibt es weiter unten im Abschnitt Optimierung einiges an Input meinerseits.
Eine Übersicht anderer Algorithmen findest du bei sklearn. Nicht alle werden einfach so mit meinem Code funktionieren. Nicht alle bieten das gleiche API – manchen fehlt etwa die „predict_proba“-Methode, die ich hier in dem Script verwende.
Wichtig: Reihenfolge der Targets
So unser Modell wurde zu Ende traininert und kann nun zur Prognose verwendet werden. Bevor wir das aber angehen, muss ich einige Abschweifungen machen, die dir einiges an Zeit ersparen werden.
Du weißt, dass wir im Grunde nur zwei Klassen/Targets haben, die wir voraussagen: 0 oder 1.
Der gezeigte Code spuckt diese Classes auch aus:
Class/Target order: [0 1]
Hier ist vor allem die Sortierung wichtig. In diesem Array steht die 0 vorne und die 1 folgt. Das ist wichtig, weil wir später ja die Wahrscheinlichkeiten für das Eintreffen von 0 bzw. 1 haben wollen. Dafür gibt es eine einfache Methode des Modells: „predict_proba“. Sie gibt für JEDE Zeile ein ARRAY (!!) bestehend aus zwei Wahrscheinlichkeiten, die in Summe 100% sind. Zur Demonstration:
[ [0.10, 0.90], [0.44, 0.56], [0.22, 0.78], ]
Hierbei steht der jeweils erste Wert für die Wahrscheinlichkeit, dass die Klasse 0 ist. Der zweite Wert steht für die Wahrscheinlichkeit, dass der Wert 1 ist.
Die Reihenfolge richtet sich immer nach dem, was in model.classes_ steht! Entsprechend interessieren uns nur der jeweils letzte Wert jedes Subarrays. Das ist nämlich das, was numerai von uns sehen will: die Wahrscheinlichkeit für die Klasse „1“.
Eigenschaften von sklearn Klassifizierungsalgorithmen
Nun haben wir unser Modell trainieren und das Objekt steht uns als „model“ zur Verfügung. „model“ hat einige Attribute und Methoden, auf die wir zugreifen können und sie sehr hilfreich sind. Je nach eingesetzten Algorithmus unterscheiden sich die Möglichkeiten natürlich.
Das API zu ExtraTreesClassifier – der Algorithmus, den ich verwende – ist HIER zu sehen.
Ich werde nicht jede Methode und jedes Attribut kommentieren.
Attribut: feature_importances_
Mit „model.feature_importances_“ kannst du auf eine Liste zurückgreifen, die besagt, wie wichtig jedes einzelne Feature ist, wenn es um die Klassifizierung geht. Das wäre quasi Feature Selection. Das resultierende Array korrespontiert mit der Featureliste, die beim Training verwendet wurde:
[ 2.56549554e-02 3.38720543e-04 2.95302177e-02 7.46299488e-02 3.81285453e-02 5.78283580e-05 1.56259473e-03 1.19001145e-02 1.30647462e-02 6.72349484e-03 3.44087894e-02 1.09712892e-01 2.83999583e-03 4.23223878e-03 8.79418127e-04 1.41646517e-03 3.25432801e-04 5.29453461e-03 5.71958375e-02 1.21031122e-03 1.48891050e-02 1.97462484e-03 4.09820424e-02 3.65735018e-02 3.12149311e-03 3.09147616e-03 4.04991472e-03 3.44421423e-03 1.00113848e-02 1.32461276e-02 2.31782142e-02 3.55888832e-02 4.70340669e-02 1.28564896e-02 2.47330887e-02 7.65534949e-04 3.48969419e-02 8.95877339e-03 5.53942866e-03 7.33380272e-03 3.57520891e-04 4.99723512e-03 1.32142531e-02 5.39496886e-04 8.31166099e-04 1.30340902e-02 2.92595644e-02 1.75575539e-03 7.74414742e-02 1.07193252e-01]
So eine Datenmenge einfach mal so auf einen Blick zu bewerten, ist nicht einfach. Wir visualisieren uns das Ergebnis und verwenden seaborn. Die paar Zeilen, wie so etwas funktioniert, findest du HIER. So etwas ist nun das Ergebnis:
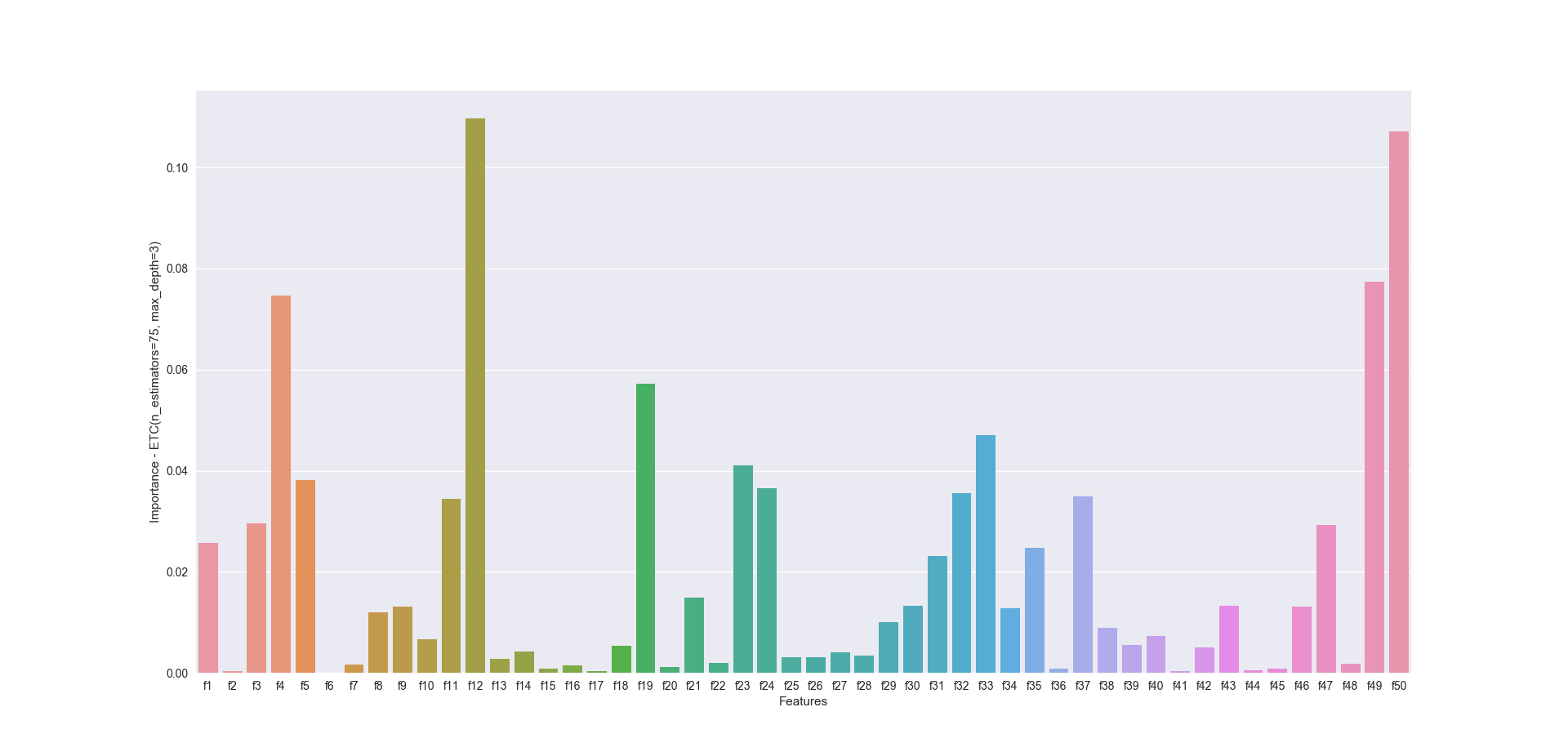
So sieht das doch schon schöner aus. Du erkennst nun für jedes Feature die Wichtigkeit bzw. den Einfluss. So ist sofort zu erkennen, dass die Features 4, 12 sowie 49, 50 einen sehr großen Einfluss haben. Du könntest nun nur diese 4 Features im Training verwenden, damit das Training deutlich schneller machen. Ob damit die Performance WIRKLICH steigt, ist eine ganz andere Frage. Probier es mal aus!
Hinweis: Nicht jeder Algorithmus spuckt dir einfach so die Wichtigkeit der Features aus und nicht unbedingt macht diese Liste Sinn und sollte einfach so verwendet werden. Testen, testen, testen!
Methode: score(X,y)
Wie der Name schon sagt, kannst du mit der score-Methode des Modells recht schnell sehen, wie genau es ist. X ist dabei deine Liste an Features und y ist die Liste an Targets. Die Methode gleicht intern den Soll-Wert (y) mit der Prognose des Modells auf Basis deiner Features (X). Das Ergebnis ist ein Wert zwischen 0 und 1, der multipliziert mit 100, als Prozentangabe gesehen werden kann. Diese Angabe sagt aus, zu wie viel Prozent dein Modell, richtig lag.
Score: 0.519073538965
Methode: predict(X)
Diese Methode nimmt alle Zeilen bestehend aus deinen Features entgegen und spuckt die gleiche Menge an Zeilen aus, die aus der prognostizierten Target bestehen.
Targets: [0 0 1 ..., 1 1 0]
Methode: predict_proba(X)
Analog, wie „predict“ gibt dir diese Methode die Wahrscheinlichkeit für jede Klasse zurück. Wir haben zwei Klassen (0, 1) so dass wir für jede Zeile bestehend aus aktuell 50 Features entsprechend ein Array bestehend aus zwei Werten zurück bekommen. Das sieht so aus:
[[ 0.50867675 0.49132325] [ 0.50274061 0.49725939] [ 0.49658421 0.50341579] ..., [ 0.49577976 0.50422024] [ 0.48780443 0.51219557] [ 0.51073931 0.48926069]]
Für den ersten Input (50 Features) ist die Wahrscheinlichkeit für das Eintreten von „1“ also 49,132%. Für den folgenden Input ist die Wahrscheinlichkeit, dass „0“ prognostiziert wird etwa 50,274%.
Performance messen
Du weißt noch nicht, wie gut das Modell nun wirklich ist. Das wollen wir jetzt rausfinden
Basis: Festgelegte Testdaten UND/ODER spezielle Validierungsdaten
Für die Bewertungen können wir zum einen die Validierungsdaten sowie die eigens erstellten Testdaten (bestehend aus 25% der Trainingsdaten) verwenden. Es wäre im Grunde nur eines nötig, ich werde aber mit Absicht beide Datensätze verwenden. Das erlaubt einen Einblick in diese Datensätze. Ihr solltet an der Stelle erwarten, dass die Performance für beide Datensätze fast gleich ist. Dem wird vielleicht nicht so sein, was für eine gewisse Diskrepanz zwischen Validierungsdaten und den Trainingsdaten spricht. So etwas lohnt näher untersucht zu werden!
Genauigkeit (Accuracy)
Zu Beginn bestimmen wir einfach, wie oft die Prognose richtig liegt. Sowohl für die Trainings- als auch für die offiziellen Validierungsdaten haben wir ja die „richtigen“ Ergebnisse bzw. Klassen/Targets vorliegen.
Das Ergebnis sieht folgendermaßen aus:
Model: Score for 25.00% of training data: 0.516288 Model: Score for nmr's own validation data : 0.510147
Für die Testdaten ist unser Modell geringfügig besser als für die Validierungsdaten. Spannend!
Mehrfache Validierung auf Basis von Teilpaketen aus dem Trainingdatensatz (Cross Validation)
sklearn bietet eine Funktion namens „cross_val_score„. Hiermit wird dein Modell mehrfach (als Standardwert habe ich 4 hinterlegt) getestet. Dabei werden jeweils andere Teile des gesamten Trainingssets verwendet. Hierzu sei die Seite Cross Validation empfohlen.
Und das Ergebnis sieht für den vierfachen Durchlauf folgendermaßen aus:
CV (4): Score for 100% of training data: 0.513990 (+-0.002208) CV (4): Score for nmr's own validation data : 0.513383 (+-0.001030)
Du siehst, dass die Genauigkeit/Score in etwa auf dem gleichen Level ist, wie bei der Modell-eigenen „score“-Methode. Zusätzlich gebe ich dir noch den durchschnittlichen Standardfehler aus. Der liegt beim Validierungsdatensatz deutlich unter dem des Trainingsdatensatzes.
Logarithmischer Verlust & Unsicherheit (Log Loss)
Der Log Loss-Wert ist für uns von besonderer Wichtigkeit. Unser Modell muss einen Log Loss erreichen, der kleiner als -log(0.5) bzw. 0.631 ist. Ansonsten qualifiziert sich unser Modell nicht für die Teilnahme am Wettbewerb. Oben habe ich einen Background-Artikel zu dem Thema verlinkt, falls dich interessiert, wie dieser Wert zustande kommt. Zur Berechnung benötigst du im Endeffekt die Targets sowie die Wahrscheinlichkeiten pro Zeile pro Klasse. Diese Daten besorgen wir uns im folgenden Teil des Codes. Nützlich ist hierbei die oben vorgestellte Methode „predict_proba“. AUch hier berechnen wir für beide Datensätze (Test/Validierung) den Log Loss.
Das Ergebnis ist zum Glück gar nicht so schlecht:
Logloss for 25.00% training data: 0.692519 Logloss for validation data: 0.692788
Wenn es um den Log Loss geht, qualifiziert sich unser Modell schon mal.
Ergebnisse für die echten Tournament-Daten
Nun haben wir einige grobe Daten zu unserem Modell und wollen damit die Tournament-Daten voraussagen. Das ist das, was wichtig ist und das reichen wir bei numerai ein.
Wahrscheinlichkeit für das Eintreffen von Target/Klasse „1“
Wie ich bereits angedeutet habe, ist die Klasse an sich für uns eher unbedeutend. Uns interessiert eher die Wahrscheinlichkeit mit der 0 bzw. 1 vorausgesagt wird. Das finden wir mit folgendem Code heraus, der auch unsere predict_proba-Methode verwendet:
Die zweite Zeile ist von besonderer Bedeutung. Du weißt noch, dass predict_proba und für jeden Input die beiden Wahrscheinlichkeiten für das Eintreten von 0 bzw. 1 liefert. Uns interessiert aber nur die Wahrscheinlichkeit für den Fall „1“. Entsprechend holen wir uns aus ALLEN Zeilen (jede besteht aus einem Array) das zweite Element des Arrays.
Jetzt speichern wir temporär alle relevanten Daten in ein pandas DataFrame – und zwar direkt so, wie es numerai haben will: ID und Wahrscheinlichkeit für 1:
Konsistenz der Ergebnisse
Weiter oben erwähne ich noch die Konsistenz. Hier fordert numerai, dass das eigene Modell eine Konsistenz von min. 75% erreicht. Das bedeutet, dass für die Daten JEDER ERA innerhalb des Validierungsdatensatzes, der Log Loss unter 0,631 liegt. Das hab ich auf die Schnelle implementiert.
Aus meinen Ergebnissen wir hier nur das rausgeholt, was den Daten aus dem Validierungsdatensatz entspricht. Das wird anhand der Ids der Zeilen abgeglichen. Anschließend wird einfach nur der Log Loss berechnet und wenn er kleiner als 0,631 ist, steigt die Konsistenz.
Das Ergebnis sieht nun folgendermaßen aus:
Calculated consistency: 58.33%
Schade. In dem Zustand wird sich unser Modell nicht qualifizieren. Wir gehen aber erstmal davon aus, dass das der Fall ist und tun so, als wenn der Wert min. 75% ist. Dann lohnt es sich das Modell zu speichern und die finale Datei für numerai zu generieren.
Ergebnisse in eine Datei speichern
Plain and simple – wenn die Datei gespeichert werden soll, dann wird das über die to_csv-Methode des pandas DataFrames gemacht:
Diese Datei kannst du im Grunde direkt bei numerai hochladen.
Modell speichern – wer weiß, vielleicht ist es wirklich gut
Damit du nicht ständig neu trainieren musst, kannst du ein Modell auf deiner HDD speichern und es jede Woche wieder verwenden. Das ist dann super schnell und wenn du ein gutes Modell hast, dann wird es eine lange Zeit sehr gute Ergebnisse liefern. Für das Abspeichern von sklearn-Modellen kann man „pickle“ verwenden. Wie du das Modell später wieder lädst, findest du schnell via Google raus.
Wir haben es geschafft! Das Grundgerüst steht. Du kannst jetzt experimentieren. Andere Algorithmen verwenden, andere Parameter testen. Du kannst auch Dinge machen, die niemand offiziell empfiehlt. Du kannst hier im Grunde nur dazu lernen!
Optimierungsmöglichkeiten & Tipps
Das soll noch nicht das Ende sein. Machine Learning ist so vielfältig und komplex. Natürlich gibt es sehr gute Möglichkeiten dein Modell zu verbessern. Einen zumindest kleinen Einblick will ich dir geben. Sei nicht böse, wenn ich dir nicht die richtig guten Wege direkt zeige. So etwas musst du selbst rausfinden und dich mit dem Thema auseinander zu setzen.
Ich werde jetzt ab hier teilweise zusammenhanglose Scripte und Codezeilen posten. Diese dienen nur der Demonstration. Du wirst sie in der Gesamtheit selbst runterprogrammieren müssen. Das oben gezeigte und auf github verfügbare Script ist sicherlich ein guter Startpunkt.
Andere Algorithmen ausprobieren
Diverse Algorithmen von sklearn
ExtraTreesCLassifier ist nicht der einzige brauchbare Algorithmus, den du mal ausprobieren solltest. Einige Vorschläge mache ich:
Beide Algorithmen haben predict_proba implementiert. Du kannst sie im Grunde so direkt verwenden. Ein Blick in die Ensembles ist IMMER lohnenswert. Damit wirst du vermutlich die besten Ergebnisse erreichen.
Voting auf Basis der Mehrheit
Besonders spannend könnte die Verwendung eines Klassifizierungssystems sein, was aus verschiedenen Algorithmen besteht. Stell dir vor du klassifizierst mit 10 verschiedenen Algorithmen und dann wird geschaut, wie viele davon eine 1 und wie viele eine 0 vorausgesagt haben. Entsprechend wird sich dann entschieden. So etwas gibt es bei sklearn ebenfalls:
Die Implementierung ist denkbar einfach:
sklearn – AdaBoost
Eine bewährte Methode ist der AdaBoost Algorithmus. sklearn implementiert AdaBoost als „AdaBoostClassifier„. Hierbei wird zuerst ein anderes von dir definiertes Modell trainiert. AdaBoost versucht im Anschluss den Fehler, den das Basismodell macht, auszugleichen. sklearn beschreibt das ganze ganz gut:
„An AdaBoost classifier is a meta-estimator that begins by fitting a classifier on the original dataset and then fits additional copies of the classifier on the same dataset but where the weights of incorrectly classified instances are adjusted such that subsequent classifiers focus more on difficult cases“
Das ganze ist ebenfalls sehr einfach umzusetzen und du könntest es gleich verwenden:
Achtung: AdaBoost führt oft zu so genanntem Overfitting. Dein Modell wird extrem gut mit den aktuellen Trainings- und Testdaten klarkommen. Wenn es aber in Zukunft komplett neue Daten sieht, wird es vermutlich komplett versagen. Also hier unbedingt aufpassen. Das passiert vor allem, wenn du extrem hohe Parameterwerte (n_estimators, max_depth, …) verwendest.
Tensorflow und Keras
Jeder hat eigentlich schon was von tensorflow gehört – das ist das Deep Neural Network-Framework von Google. Es ist mächtig. Du wirst damit vermutlich sehr gute Ergebnisse erzielen. Der Umgang damit ist allerdings nicht so einfach, wie er es mit sklearn ist. Das beginnt schon mit der Installation von Tensorflow, wenn man GPU Unterstützung haben will. Da muss man aber durch!
Ich empfehle dir „Keras„, das in der Lage ist Tensorflow als Backend zu verwenden. Damit ist das Handling etwas einfacher.
Beispielsweise kann ein recht einfaches Deep Neural Network, das am Ende in der Lage ist, binäre Klassifizierung durchzuführen folgendermaßen aus:
Du erkennst hier ein einfaches Neuronales Netzwerk bestehend aus:
- Input Layer mit 50 Neuronen
- Vier Hidden Layer (450, 50, 12, 4 Neuronen)
- Dazwischen teilweise Dropout-Layer (entfernt einen bestimmten Teil der Zwischenergebnisse)
- Output Layer – bestimmt 0 bzw. 1
Auch hier siehst du, dass „predict“ und „predict_proba“ implementiert sind.
Achtung: Schau dir die Dokumentation von Keras genau an. Dann wirst du feststellen, dass „predict“ bereits die Wahrscheinlichkeiten ausgibt. Die Umwandlung in 0 bzw. 1 wirst du also alleine vornehmen müssen. Das sollte aber kein großes Problem sein. Wahrscheinlich wird mit der Zeit „predict_proba“ entfernt. Achte da auf jeden Fall drauf.
Gradient Boosting mit XGBoost
XGBoost gilt als Geheimwaffen und man sieht immer wieder, das größere Wettbewerbe damit zuverlässig gewonnen werden (siehe z.B. auf kaggle.com). Auch bei der numerai-Competition wird XGBoost ganz gerne verwendet. Das API ist ebenfalls recht einfach. Das Installieren kann auch hier zur Herausforderung werden. Auf Beispiele verzichte ich, weil es im github-Account quasi für alles ein Beispiel gibt:
Andere Parameter testen
Jeder Algorithmus hat in der Regel einzigartige Parameter, die die Performance des Modells beeinflussen. Es lohnt sich etwas Zeit für das Optimieren der Parameter aufzuwenden. Das kannst du von Hand machen. Das ist aber in der Regel zeitaufwendig und nicht wirklich lohnenswert. Viel besser ist das Ausweichen auf automatisierte Lösungen. Hier kannst du mal bei Google suchen, ob dein Lieblingsframework vielleicht schon ein Paket zum Optimieren von Hyperparametern hat. Etwas Input zu dem Thema gibt es hier meinerseits:
tpot (Hyperparameter Optimierung für sklearn)
Mit tpot werden automatisch alle in Frage kommenden Modell sowie alle in Frage kommenden Parameter dieser Modelle durchgetestet. Das ist zeitaufwendig. Also stell dich auf lange Wartezeiten ein. Es wird sich aber lohnen.
Auch hier ist das Verwenden recht einfach:
GridSearchCV
Wenn du nicht unbedingt nach verschiedenen Algorithmen innerhalb von sklearn suchst, sondern bereits einen Algorithmus verfeinern willst, dann schau dir GridSearchCV an. Hier kannst du eine Parameterliste aufbauen und deinen Algorithmus für jede Kombination testen lassen. Das sieht z.B. mit dem ExtraTreesClassifier so aus:
Als Ergebnis wird uns dann auch folgendes präsentiert:
Best score found: 0.5110404115616327
Params used:
{'n_jobs': 1, 'n_estimators': 30, 'max_depth': 5}
So kommt man schnell an die besten Parameter für ein Modell.
Optimierung für Keras
Schaut euch hierzu „Hyperas“ an. Verlinkt ist das github-Profil des Projekts. Dort gibt es ein großes ausführliches Beispiel, um die Parameter eines Keras-Classifiers zu optimieren. Das ganze lässt sich aber auch recht einfach selbst implementieren – letzteres habe ich gemacht (Hyperas hat bei mir nicht funktioniert) und erziele mit einem recht einfachen DNN sehr gute Ergebnisse.
Datenbasis verbessern
Die besten Ergebnisse wirst du aber erzielen, wenn du dich lange und ausführlich mit den Daten befasst – noch bevor du irgendetwas trainierst. So solltest du dir die Fragen stelle, welche Features vielleicht am wichtigsten sind. Oben habe ich bereits eine Möglichkeit gezeigt, „wichtige Features“ zu extrahieren. Einige Algorithmen von sklearn bieten dies recht bequem über Attribute nach dem Training an. Es lohnt sich hier etwas zu testen. Ansonsten gibt es noch die automatischen Lösungen:
BorutaPy
Im Fall von „feature_importance_“ auf Basis von z.B. ExtraTreesClassifiert hat man oft ein kleines Problem. Unter Umständen verliert man wichtige Daten und die Performance sinkt. Diese Features sind eben nur eine Untergruppe, mit der man fast (!) genauso gut arbeiten könnte. BorutaPy verfolgt da ein anderes Ziel. Hierzu sei das Paper empfohlen. Es sucht nicht nach einer Gruppe von Features, wo der Fehler minimal wird, sondern nach einer Gruppe von Features, bei der es keinen Fehler gibt. Das ist durchaus spannend.
Auf github gibt es ein schönes Beispiel für die Anwendung:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
# load X and y
# NOTE BorutaPy accepts numpy arrays only, hence the .values attribute
X = pd.read_csv('examples/test_X.csv', index_col=0).values
y = pd.read_csv('examples/test_y.csv', header=None, index_col=0).values
y = y.ravel()
# define random forest classifier, with utilising all cores and
# sampling in proportion to y labels
rf = RandomForestClassifier(n_jobs=-1, class_weight='auto', max_depth=5)
# define Boruta feature selection method
feat_selector = BorutaPy(rf, n_estimators='auto', verbose=2, random_state=1)
# find all relevant features - 5 features should be selected
feat_selector.fit(X, y)
# check selected features - first 5 features are selected
feat_selector.support_
# check ranking of features
feat_selector.ranking_
# call transform() on X to filter it down to selected features
X_filtered = feat_selector.transform(X)
Gegeneinander modellieren
Eine weitere Idee könnte es sein, viele Modelle zu bauen, deren Trainingsdaten nur die einzelnen ERAs umfassen. Anschließend trainierst du dieses Modell und verwendest als Testdaten jedes andere ERA-Paket. Dann wirst du feststellen, dass dein Modell manche ERAs sehr gut und manche total schlecht voraussagen kann. Daraus kannst du Schlüsse ziehen – eventuell hast du da Ausreißer gefunden, die nicht so viel für das gesamte Modell beitragen oder die Performance unnötig runterziehen.
MinePy
MinePy ist vergleichbar mit BorutyPy. Es versucht die Features zu extrahieren, die einen maximalen Informationsgehalt haben. Damit kannst du zusehen, dass du nicht mit 50 sondern vielleicht mit 25 Features trainierst.
Es gibt noch weitaus mehr Methoden, die du verwenden könntest. sklearn bietet z.B. noch Lasso oder Ridge. Im Allgemeinen ist ein Blick auf den Bereich „Feature selection“ nicht verkehrt. Dort hast du mehr als genug Input.
Pearson-Korrelationskoeffizient
Von Interesse könnte auch die Korrelation der einzelnen Features untereinander sein. Eventuell haben wir Features, die stark miteinander korrelieren und damit ggf. direkt ausgeschlossen würden könnten (zumindest eines der beiden Features). Schauen wir uns das doch mal mit seaborn an:
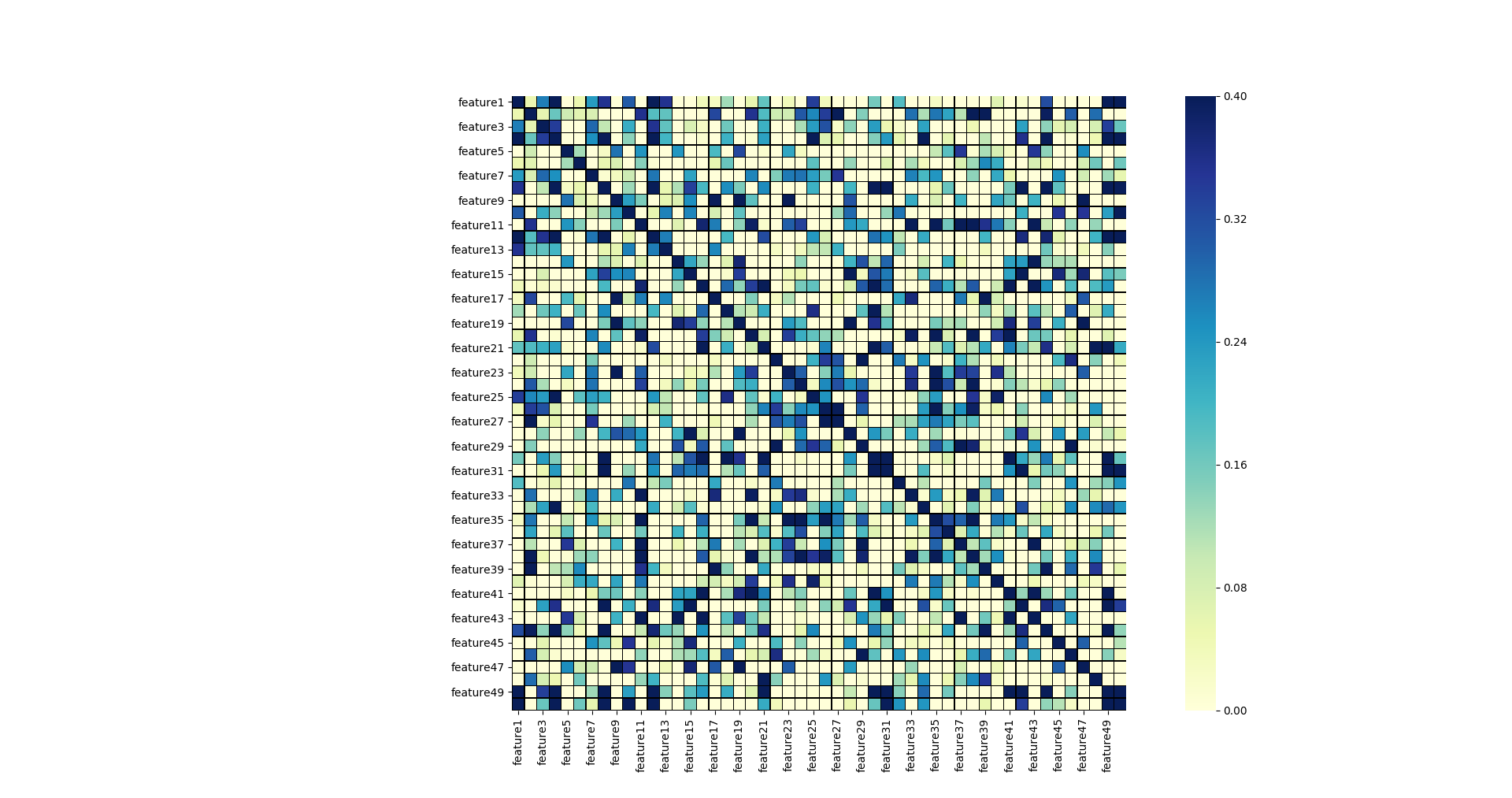
Auf den ersten Blick sehen wir nicht viel Korrelation. Offenbar korrelieren aber die folgenden Feature-Paare:
| Art | Features |
|---|---|
| Stark | 03 und 04 |
| Stark | 26 und 27 |
| Stark | 30 und 31 |
| Stark | 49 und 50 |
| Etwas schwächer | 12 und 13 |
| Etwas schwächer | 23 und 24 |
| Etwas schwächer | 35 und 36 |
Aber Achtung: achtet in dem Fall auf die Skalierung. Die größte Korrelation wäre bei mir 0,4. Das sorgt dafür, dass ich die Differenzen besser erkenne, aber unter Umstände die Korrelation überbewerte. Es lohnt sich daher lieber eine Skala zwischen 0 und 1 zu wählen. Im Folgenden siehst du die korrigierte Heatmap.
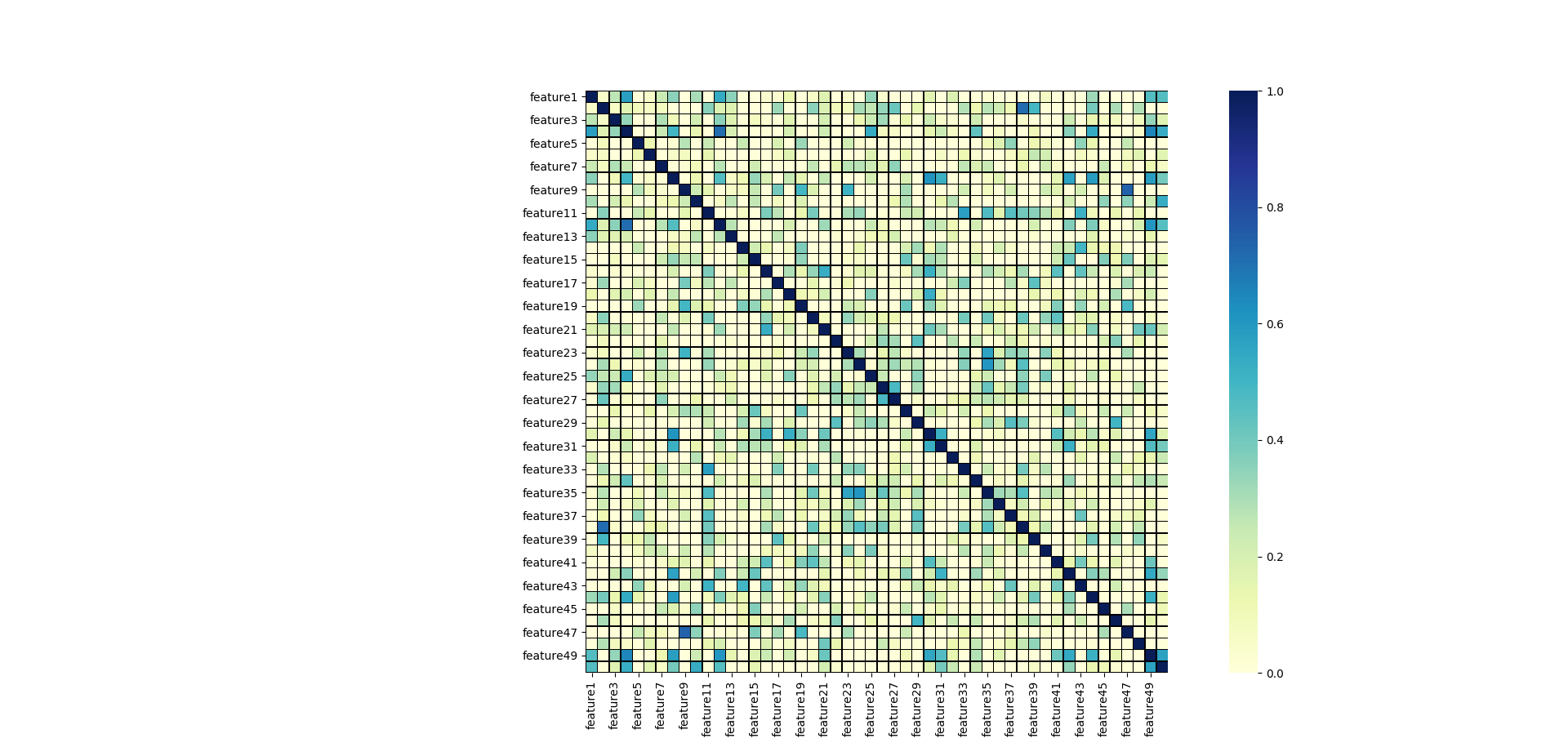
Jetzt erkennt man gut, dass es eine gewisse Korrelation zwischen den oben genannten Features gibt, aber diese nicht wirklich „stark“ ist. Du könntest bei der Auswahl der Features also ggf. auf 49 verzichten, wenn du 50 mit aufnimmst. Auch hier lohnt das Ausprobieren – zumal wir keine wirklich stark sichtbare Korrelation sehen.
Wir optimieren unser numer.ai-Script
Wir haben oben das Script. Das Modell produziert die folgenden Scores.
Model: Score for 25.00% of training data: 0.516288 Model: Score for nmr's own validation data : 0.510052 CV (4): Score for 100% of training data: 0.514001 (+-0.002208) CV (4): Score for nmr's own validation data : 0.513383 (+-0.001022) Logloss for 25.00% training data: 0.692519 Logloss for validation data: 0.692789 Calculated consistency: 58.33%
Wir sehen, dass der Log Loss offenbar in Ordnung ist. Allerdings ist die Konsistenz zu gering.
Wir wählen nur bestimmte Features!
Wir orientieren uns an model.feature_importance_ und wählen die folgenden Features aus:
[1, 3, 4, 5, 11, 12, 19, 23, 24, 31, 32, 33, 35, 37, 47, 49, 50]
Resultat:
Model: Score for 25.00% of training data: 0.518140 Model: Score for nmr's own validation data : 0.508373 CV (4): Score for 100% of training data: 0.515410 (+-0.001741) CV (4): Score for nmr's own validation data : 0.514492 (+-0.003293) Logloss for 25.00% training data: 0.692492 Logloss for validation data: 0.692781 Calculated consistency: 66.67%
Überraschenderweise haben sich die Werte fast überall verbessert.
Vielleicht etwas Feature Engineering?
Eine sehr einfache Idee automatisch aus den aktuell 17 ausgewählten Features eine größere Anzahl aufzubauen ist preprocessing.PolynomialFeatures. Ich schalte diese Transformationen einfach in meine Preprocessing-Pipeline:
Hier werden aus den aktuell 17 Features einfach mal in Summe 1140 konstruiert. Das muss nicht unbedingt klug sein. An der Stelle lohnt sich immer wieder mal das Testen!
Das Ergebnis lässt sich auch direkt sehen:
Model: Score for 25.00% of training data: 0.514646 Model: Score for nmr's own validation data : 0.511541 CV (4): Score for 100% of training data: 0.513990 (+-0.001398) CV (4): Score for nmr's own validation data : 0.506681 (+-0.002543) Logloss for 25.00% training data: 0.692572 Logloss for validation data: 0.692682 Calculated consistency: 75.00%
Das Modell scheint etwas ungenauer zu sein, dafür ist es jetzt Konsistent. Ich vermute es liegt aber hart an der Grenze 😉
Upload der Ergebnisse
Die Ergebnisdatei wurde generiert. Wir können mal reinschauen:
Sieht gut aus. Jetzt kann man es mal hochladen:
Überraschung: Wir sind durch alle Prüfungen gekommen – was ich ehrlich gesagt aufgrund der Einfachheit des Modells nicht erwartet hätte.
Fazit und Fragen
Ich hoffe, die kleine Einführung in den Wettbewerb hat dich weiter gebracht. Ich wünsche dir viel Erfolg und einen richtig starken PC, um bei der Challenge mitzumachen 😉 Bei Fragen kannst du gerne einen Kommentar hinterlassen oder eine E-Mail schreiben. Den Artikel habe ich innerhalb von 6:30 runtergeschrieben. Wenn du einige Formulierungen unklar/komisch findest, kannst du mir das gerne sagen. Am Ende soll es ja verständlich sein!
Ansonsten: kompletter Quellcode auf github.com
Eine letzte Bemerkung
Wenn du ernsthaft an der Challenge teilnehmen willst, solltest du dir mal das Leaderboard anschauen. Dann wirst du feststellen, dass fast alle der Top 100 auf Basis der Validierungsdaten einen Log Loss von ~0,690 erreichen. Das bedeutet für z.B. unser simples Modell, dass wir zwar gut genug sind, aber weit von Top 100 entfernt. Deine Aufgabe ist es also ab hier einen Weg zu finden ein solides allgemeines Modell zu finden, das in diesem Bereich liegt.


